
Meta-learning three-factor learning rules for reward-driven training of RNNs
We have devised a method for discovering plasticity rules for reward-driven training of recurrent networks.
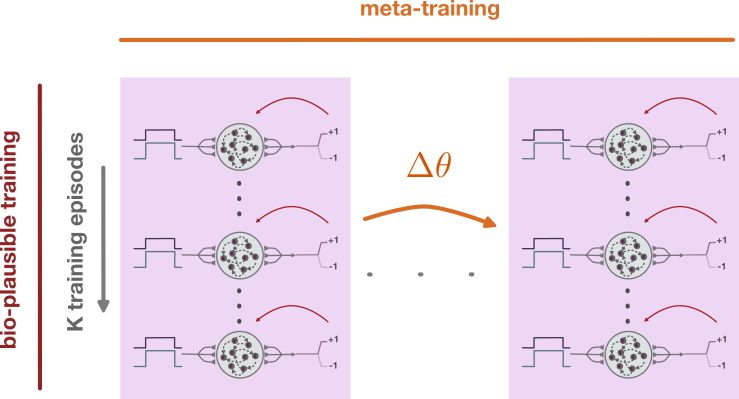
Background
Here is a very coarse pre-print sketching out the ideas submitted at NeurIPS 2025 (without results) (see here) to test for interest (and ensure that when I present it as a poster in upcomming conferences I will have proof of the ownership of the ideas in case someone would try to claim them1 2) and pre-printed on 13th of August 2025 here.\
The starting point of the idea was the grad-log density/score function estimator similar to the one I developed in my PhD thesis applied on reinforcement learning settings. :) [ODEs for SDEs - Probability flow ODEs]
Presentations
Presented as a poster at: Champalimaud Neuro-cybernetics Symposium - Oct 2025 (see here for more info)
Upcomming presentations:
- NeurIPS 2025 - NeurReps workshop
- NeurIPS 2025 - WiML workshop
FYI
If someone happens to claim that this is work/ideas/dreams that belong to my previous lab, please read the email exchange here that explicitly states that I am free to pursue this project because we never discussed anything other than me proposing to use a three-factor rule here. And see here the last stage of the project I was involved in that used low-rank networks and two-factor rules (only pre- and post-synaptic rates). (Also this project had no eligibility traces or any sort of feedback).
Let’s just say that I am very apt at pattern recognision, which extends to recognising (and predicting) patterns of behaviour of certain individuals. 😘 ↩
Although I still wonder who would be so creatively inert and intellectually vacuous to want to claim my or other people’s ideas instead of generating their own. 🤔 ↩